Home
/
Articles
/
AI Inference: Bringing AI Closer to the User
AI inference is where the magic of a trained model truly comes alive. While training an AI model is resource-intensive and typically occurs in centralized environments, inference is the real-time deployment of that model, generating predictions on new data continuously and at scale. A solid understanding of inference is crucial to delivering fast, reliable, and cost-efficient AI experiences.
Types of Inference Tasks
AI inference powers a wide range of applications. Key task types include:
Classification: Determining categories, e.g., is this email spam? Is this tumor malignant?
Regression: Predicting continuous values, e.g., stock prices, temperature, or energy consumption.
Detection & Segmentation: Identifying objects in video frames or medical scans, such as detecting pedestrians or tumors.
Recommendation & Personalization: Suggesting content in streaming apps, e-commerce platforms, or news feeds.
Each task comes with unique computational demands and performance expectations, influencing how and where inference should be deployed.
Performance Metrics for Inference
Inference isn’t only about accuracy; performance also involves speed, efficiency, and reliability:
Latency: Time between input and output. Critical for real-time applications.
Throughput: Number of inferences per second. Important for high-demand systems.
Accuracy & Reliability: Inference must closely match the model’s training performance.
Energy Efficiency: Vital for edge devices with limited power resources.
Balancing these metrics ensures AI systems are practical and user-friendly.
Proximity to End Users, Why It Matters
Where inference occurs, close to the user or in the cloud, has major implications:
Latency & Responsiveness:
Cloud inference: 50–200ms delays typical; can be noticeable in fast applications. Regional data centers can help reduce these delays by placing servers closer to users.
Edge inference: Millisecond-level responses ideal for autonomous vehicles, AR/VR, and industrial automation.
Bandwidth Efficiency: Edge inference reduces the need to transmit large images, videos, or sensor data to the cloud.
Privacy & Security: Processing data locally minimizes exposure of sensitive information, aiding compliance with regulations like GDPR or HIPAA.
Reliability & Resilience: Edge AI functions offline or with intermittent connectivity, essential for drones, remote monitoring, and disaster-response systems. Regional data centers also provide redundancy and load balancing to ensure services remain available even during localized outages.
Cost Optimization: Local inference can reduce recurring cloud costs, while hybrid architectures leverage regional data centers to balance efficiency, latency, and scale.
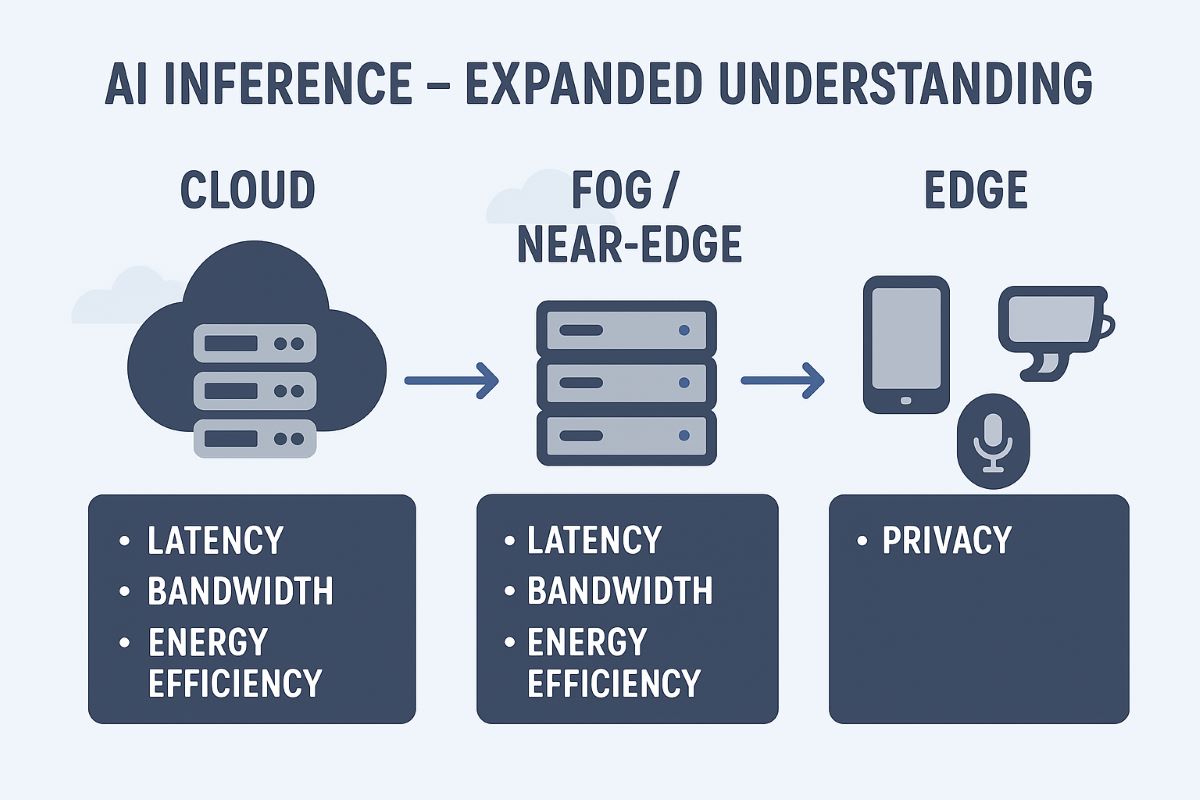
Technical Approaches to Proximity
AI deployment strategies vary depending on where inference occurs:
Edge AI: Models run on devices like smartphones, IoT gadgets, or embedded systems. Techniques such as quantization, pruning, and knowledge distillation make models smaller and faster.
Fog / Near-Edge Computing: Intermediate servers or regional data centers process data close to users, balancing latency, bandwidth, and power consumption.
Cloud AI: Centralized servers handle large models and heavy workloads but may incur higher latency, data transfer costs, and potential privacy concerns. Using regional data centers can mitigate latency while still providing centralized compute power.
Practical Examples
Use Case
Latency Requirement
Best Proximity
Notes
Autonomous car braking
<50ms
On-device / edge
Safety-critical; cannot rely on cloud
Smart camera security
<100ms
Edge
Only sends alerts, not raw video
Video streaming recommendations
200–500ms
Cloud / regional data center
Cloud handles large datasets; regional data centers reduce delay
Industrial sensors
<10ms
Local edge / fog
Immediate fault detection
Voice assistants
50–200ms
Hybrid
On-device wake word, cloud or regional data centers for complex queries
Strategic Takeaways
Proximity is critical for latency-sensitive applications. Real-time or safety-critical tasks almost always require edge inference.
Hybrid models are the future. Local inference handles routine tasks, while cloud and regional data centers handle heavier processing closer to users.
Optimization is key. Smaller models, efficient algorithms, and specialized hardware (TPUs, GPUs, NPUs) make edge AI feasible.
User trust and experience rely on speed and privacy. Faster responses combined with robust data protection drive adoption.
AI inference is not just a backend process, it’s the bridge between advanced AI models and the user experience. By understanding the types of tasks, performance metrics, and proximity strategies, including the strategic use of regional data centers, organizations can deliver AI that is fast, reliable, and trustworthy, bringing intelligent systems closer to where they matter most: in the hands of users.